The Facial Action Coding System (FACS)
Developed by Dr Paul Ekman and Dr Wallace Friesen in 1978, the Facial Action Coding System provides a comprehensive taxonomy of all anatomically distinct facial muscle actions. FACS identifies 44 discrete Action Units (AUs) that combine to form every possible human facial expression.
FACS is the foundational framework for emotion analysis in clinical psychology, lie detection research, human-computer interaction design, and — most relevantly — AI-powered emotion recognition systems.
How EchoDepth Maps AUs to Emotion
EchoDepth analyses all 44 FACS Action Units from each video frame, computing activation intensity for each AU. These activation values are then processed through a classification model that maps AU combination patterns to discrete emotional states.
Key AU-to-emotion mappings relevant to event analytics:
| Action Unit(s) | Muscle / Movement | Signal Interpretation |
|---|---|---|
| AU1 + AU2 | Inner/outer brow raise | Surprise, interest, engagement |
| AU4 | Brow lowerer (corrugator) | Confusion, concern, concentration |
| AU6 + AU12 | Cheek raise + lip corner pull | Genuine (Duchenne) smile — delight |
| AU12 only | Lip corner pull | Social smile — potentially performative |
| AU14 | Dimpler (unilateral lip) | Scepticism, uncertainty |
| AU17 | Chin raiser | Doubt, discomfort |
| AU23 + AU24 | Lip tightener / pressor | Suppressed emotion, withholding |
| AU27 | Mouth stretch / jaw drop | Surprise — genuine reaction |
| Low activity | Reduced AU engagement | Disengagement, low interest |
VAD Modelling — Valence, Arousal, Dominance
Beyond discrete emotion classification, EchoDepth also models emotional states in the VAD (Valence, Arousal, Dominance) dimensional space. This provides a richer picture of emotional experience:
- Valence — how positive or negative the emotional experience is (−1 to +1)
- Arousal — the intensity or energy level of the emotion (0 to 1)
- Dominance — the degree of control or agency the person feels (0 to 1)
In event analytics, VAD modelling adds nuance: a high-arousal, high-valence response (excited engagement) is very different from a high-arousal, low-valence response (anxiety or confusion-triggered stress).
Confidence, Instability, and Net Confidence
EchoDepth Events produces three primary derived signals for event analytics:
- Confidence Score: A composite measure of positive emotional engagement signals — combining engagement, delight, and interest AU patterns with high valence VAD scores.
- Instability Score: A measure of ambivalence, conflicting signals, and confusion — elevated when confusion AUs (AU4), scepticism AUs (AU14), and low valence signals co-occur.
- Net Confidence: Confidence minus Instability, normalised to a −1 to +1 scale. The headline signal for overall visitor emotional disposition in any zone.
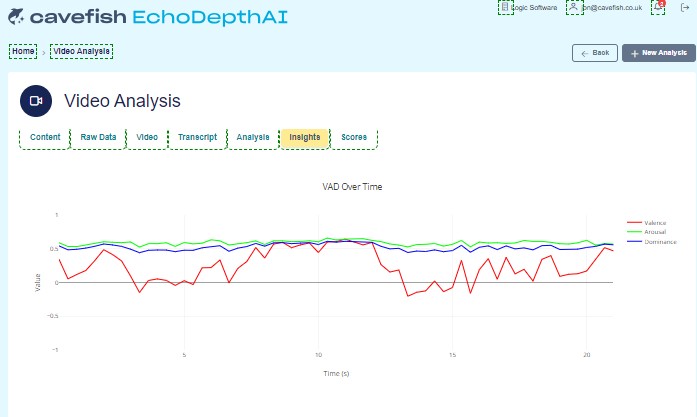
Live VAD (Valence, Arousal, Dominance) signal output from the EchoDepth platform during a real session
Real-Time Processing Architecture
EchoDepth Events processes video feeds on an edge processing unit deployed at the event venue. This edge architecture is fundamental to the privacy guarantee:
- Video frames are processed locally — never transmitted over a network
- AU extraction occurs in under 50ms per frame
- Derived signal scores are the only data that leaves the edge device
- Typical end-to-end latency from capture to dashboard display: <3 seconds
Emotional trajectory output — Confidence, Composure, Enthusiasm and Clarity tracked second by second
Accuracy and Validation
EchoDepth's FACS engine has been developed and validated against the standard academic FACS corpora and internal event deployment datasets. AU detection accuracy is highest in standard event lighting conditions (direct or diffuse artificial lighting) and standard frontal-to-near-frontal camera angles.
The platform is designed for population-level insight — aggregate zone and temporal analytics — rather than individual psychological profiling. This population-level focus is both the source of its business value and its privacy-compatible design.

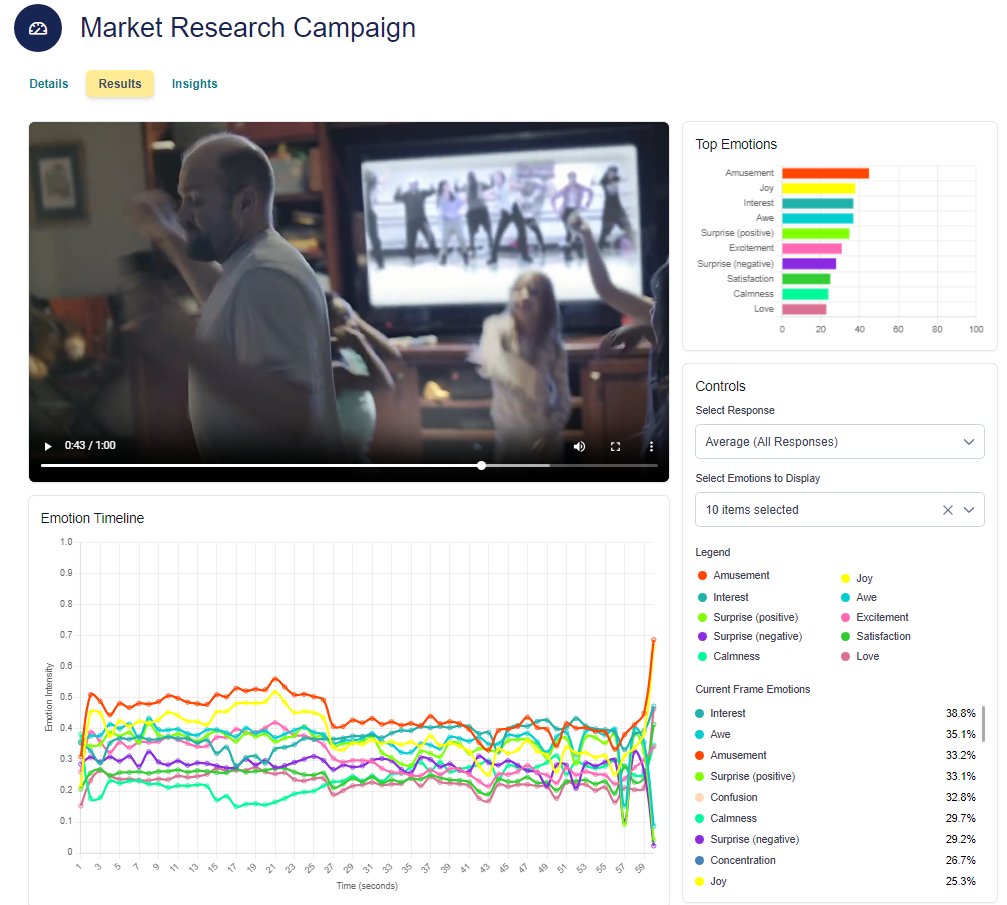
Real-time emotion timeline output — discrete emotion scores updated frame by frame across a live session